 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTouch++: A Multimodal Dataset with Vision-Based Tactile Enhancement for Bimanual Manipulation
Apr 22, 2026Embodied intelligence has advanced rapidly in recent years; however, bimanual manipulation-especially in contact-rich tasks remains challenging. This is largely due to the lack of datasets with rich physical interaction signals, systematic task organization, and sufficient scale. To address these limitations, we introduce the VTOUCH dataset. It leverages vision based tactile sensing to provide high-fidelity physical interaction signals, adopts a matrix-style task design to enable systematic learning, and employs automated data collection pipelines covering real-world, demand-driven scenarios to ensure scalability. To further validate the effectiveness of the dataset, we conduct extensive quantitative experiments on cross-modal retrieval as well as real-robot evaluation. Finally, we demonstrate real-world performance through generalizable inference across multiple robots, policies, and tasks.
DPC-VQA: Decoupling Quality Perception and Residual Calibration for Video Quality Assessment
Apr 14, 2026Recent multimodal large language models (MLLMs) have shown promising performance on video quality assessment (VQA) tasks. However, adapting them to new scenarios remains expensive due to large-scale retraining and costly mean opinion score (MOS) annotations. In this paper, we argue that a pretrained MLLM already provides a useful perceptual prior for VQA, and that the main challenge is to efficiently calibrate this prior to the target MOS space. Based on this insight, we propose DPC-VQA, a decoupling perception and calibration framework for video quality assessment. Specifically, DPC-VQA uses a frozen MLLM to provide a base quality estimate and perceptual prior, and employs a lightweight calibration branch to predict a residual correction for target-scenario adaptation. This design avoids costly end-to-end retraining while maintaining reliable performance with lower training and data costs. Extensive experiments on both user-generated content (UGC) and AI-generated content (AIGC) benchmarks show that DPC-VQA achieves competitive performance against representative baselines, while using less than 2% of the trainable parameters of conventional MLLM-based VQA methods and remaining effective with only 20\% of MOS labels. The code will be released upon publication.
FireRed-OCR Technical Report
Mar 02, 2026We present FireRed-OCR, a systematic framework to specialize general VLMs into high-performance OCR models. Large Vision-Language Models (VLMs) have demonstrated impressive general capabilities but frequently suffer from ``structural hallucination'' when processing complex documents, limiting their utility in industrial OCR applications. In this paper, we introduce FireRed-OCR, a novel framework designed to transform general-purpose VLMs (based on Qwen3-VL) into pixel-precise structural document parsing experts. To address the scarcity of high-quality structured data, we construct a ``Geometry + Semantics'' Data Factory. Unlike traditional random sampling, our pipeline leverages geometric feature clustering and multi-dimensional tagging to synthesize and curate a highly balanced dataset, effectively handling long-tail layouts and rare document types. Furthermore, we propose a Three-Stage Progressive Training strategy that guides the model from pixel-level perception to logical structure generation. This curriculum includes: (1) Multi-task Pre-alignment to ground the model's understanding of document structure; (2) Specialized SFT for standardizing full-image Markdown output; and (3) Format-Constrained Group Relative Policy Optimization (GRPO), which utilizes reinforcement learning to enforce strict syntactic validity and structural integrity (e.g., table closure, formula syntax). Extensive evaluations on OmniDocBench v1.5 demonstrate that FireRed-OCR achieves state-of-the-art performance with an overall score of 92.94\%, significantly outperforming strong baselines such as DeepSeek-OCR 2 and OCRVerse across text, formula, table, and reading order metrics. We open-source our code and model weights to facilitate the ``General VLM to Specialized Structural Expert'' paradigm.
ELIQ: A Label-Free Framework for Quality Assessment of Evolving AI-Generated Images
Feb 03, 2026Generative text-to-image models are advancing at an unprecedented pace, continuously shifting the perceptual quality ceiling and rendering previously collected labels unreliable for newer generations. To address this, we present ELIQ, a Label-free Framework for Quality Assessment of Evolving AI-generated Images. Specifically, ELIQ focuses on visual quality and prompt-image alignment, automatically constructs positive and aspect-specific negative pairs to cover both conventional distortions and AIGC-specific distortion modes, enabling transferable supervision without human annotations. Building on these pairs, ELIQ adapts a pre-trained multimodal model into a quality-aware critic via instruction tuning and predicts two-dimensional quality using lightweight gated fusion and a Quality Query Transformer. Experiments across multiple benchmarks demonstrate that ELIQ consistently outperforms existing label-free methods, generalizes from AI-generated content (AIGC) to user-generated content (UGC) scenarios without modification, and paves the way for scalable and label-free quality assessment under continuously evolving generative models. The code will be released upon publication.
Decoupling Perception and Calibration: Label-Efficient Image Quality Assessment Framework
Jan 28, 2026Recent multimodal large language models (MLLMs) have demonstrated strong capabilities in image quality assessment (IQA) tasks. However, adapting such large-scale models is computationally expensive and still relies on substantial Mean Opinion Score (MOS) annotations. We argue that for MLLM-based IQA, the core bottleneck lies not in the quality perception capacity of MLLMs, but in MOS scale calibration. Therefore, we propose LEAF, a Label-Efficient Image Quality Assessment Framework that distills perceptual quality priors from an MLLM teacher into a lightweight student regressor, enabling MOS calibration with minimal human supervision. Specifically, the teacher conducts dense supervision through point-wise judgments and pair-wise preferences, with an estimate of decision reliability. Guided by these signals, the student learns the teacher's quality perception patterns through joint distillation and is calibrated on a small MOS subset to align with human annotations. Experiments on both user-generated and AI-generated IQA benchmarks demonstrate that our method significantly reduces the need for human annotations while maintaining strong MOS-aligned correlations, making lightweight IQA practical under limited annotation budgets.
Q-Bench-Portrait: Benchmarking Multimodal Large Language Models on Portrait Image Quality Perception
Jan 26, 2026Recent advances in multimodal large language models (MLLMs) have demonstrated impressive performance on existing low-level vision benchmarks, which primarily focus on generic images. However, their capabilities to perceive and assess portrait images, a domain characterized by distinct structural and perceptual properties, remain largely underexplored. To this end, we introduce Q-Bench-Portrait, the first holistic benchmark specifically designed for portrait image quality perception, comprising 2,765 image-question-answer triplets and featuring (1) diverse portrait image sources, including natural, synthetic distortion, AI-generated, artistic, and computer graphics images; (2) comprehensive quality dimensions, covering technical distortions, AIGC-specific distortions, and aesthetics; and (3) a range of question formats, including single-choice, multiple-choice, true/false, and open-ended questions, at both global and local levels. Based on Q-Bench-Portrait, we evaluate 20 open-source and 5 closed-source MLLMs, revealing that although current models demonstrate some competence in portrait image perception, their performance remains limited and imprecise, with a clear gap relative to human judgments. We hope that the proposed benchmark will foster further research into enhancing the portrait image perception capabilities of both general-purpose and domain-specific MLLMs.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
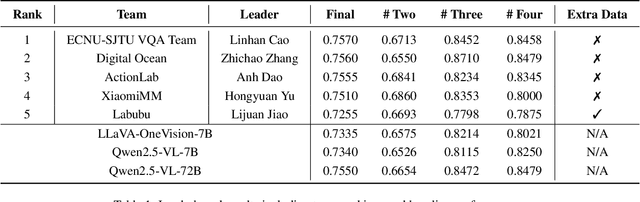
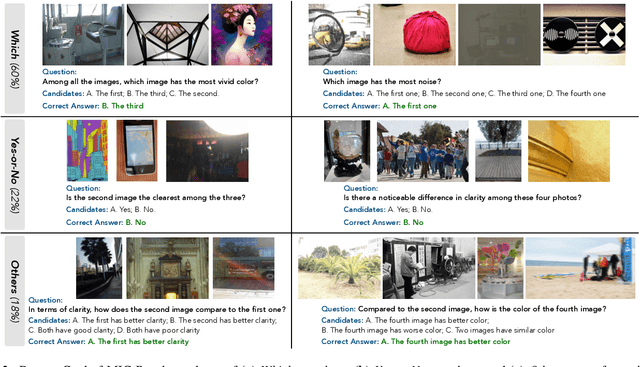
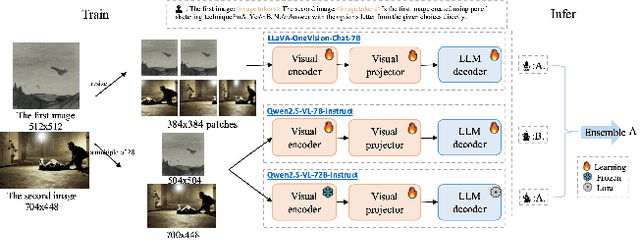
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
Sekai: A Video Dataset towards World Exploration
Jun 18, 2025Video generation techniques have made remarkable progress, promising to be the foundation of interactive world exploration. However, existing video generation datasets are not well-suited for world exploration training as they suffer from some limitations: limited locations, short duration, static scenes, and a lack of annotations about exploration and the world. In this paper, we introduce Sekai (meaning ``world'' in Japanese), a high-quality first-person view worldwide video dataset with rich annotations for world exploration. It consists of over 5,000 hours of walking or drone view (FPV and UVA) videos from over 100 countries and regions across 750 cities. We develop an efficient and effective toolbox to collect, pre-process and annotate videos with location, scene, weather, crowd density, captions, and camera trajectories. Experiments demonstrate the quality of the dataset. And, we use a subset to train an interactive video world exploration model, named YUME (meaning ``dream'' in Japanese). We believe Sekai will benefit the area of video generation and world exploration, and motivate valuable applications.
Training Superior Sparse Autoencoders for Instruct Models
Jun 09, 2025As large language models (LLMs) grow in scale and capability, understanding their internal mechanisms becomes increasingly critical. Sparse autoencoders (SAEs) have emerged as a key tool in mechanistic interpretability, enabling the extraction of human-interpretable features from LLMs. However, existing SAE training methods are primarily designed for base models, resulting in reduced reconstruction quality and interpretability when applied to instruct models. To bridge this gap, we propose $\underline{\textbf{F}}$inetuning-$\underline{\textbf{a}}$ligned $\underline{\textbf{S}}$equential $\underline{\textbf{T}}$raining ($\textit{FAST}$), a novel training method specifically tailored for instruct models. $\textit{FAST}$ aligns the training process with the data distribution and activation patterns characteristic of instruct models, resulting in substantial improvements in both reconstruction and feature interpretability. On Qwen2.5-7B-Instruct, $\textit{FAST}$ achieves a mean squared error of 0.6468 in token reconstruction, significantly outperforming baseline methods with errors of 5.1985 and 1.5096. In feature interpretability, $\textit{FAST}$ yields a higher proportion of high-quality features, for Llama3.2-3B-Instruct, $21.1\%$ scored in the top range, compared to $7.0\%$ and $10.2\%$ for $\textit{BT(P)}$ and $\textit{BT(F)}$. Surprisingly, we discover that intervening on the activations of special tokens via the SAEs leads to improvements in output quality, suggesting new opportunities for fine-grained control of model behavior. Code, data, and 240 trained SAEs are available at https://github.com/Geaming2002/FAST.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.